Vision Transformers for Medical Data
The remarkable performances of the recent large-scale NLP models inspired researchers to apply the very versatile transformer neural network architecture to vision tasks. Since 2015, computer vision tasks have been dominated by CNN architectures, but nowadays, transformers are considered as a potential alternative.
Transformers: Definition
Transformers were first used in NLP on machine translation tasks (Vaswani et al. 2017). Its main component is the self-attention layer.
Self-attention
Given a sequence of items, self-attention estimates the relevance of one item relatively to the others. It is an aggregation of the global information and a transformation of the original sequence.
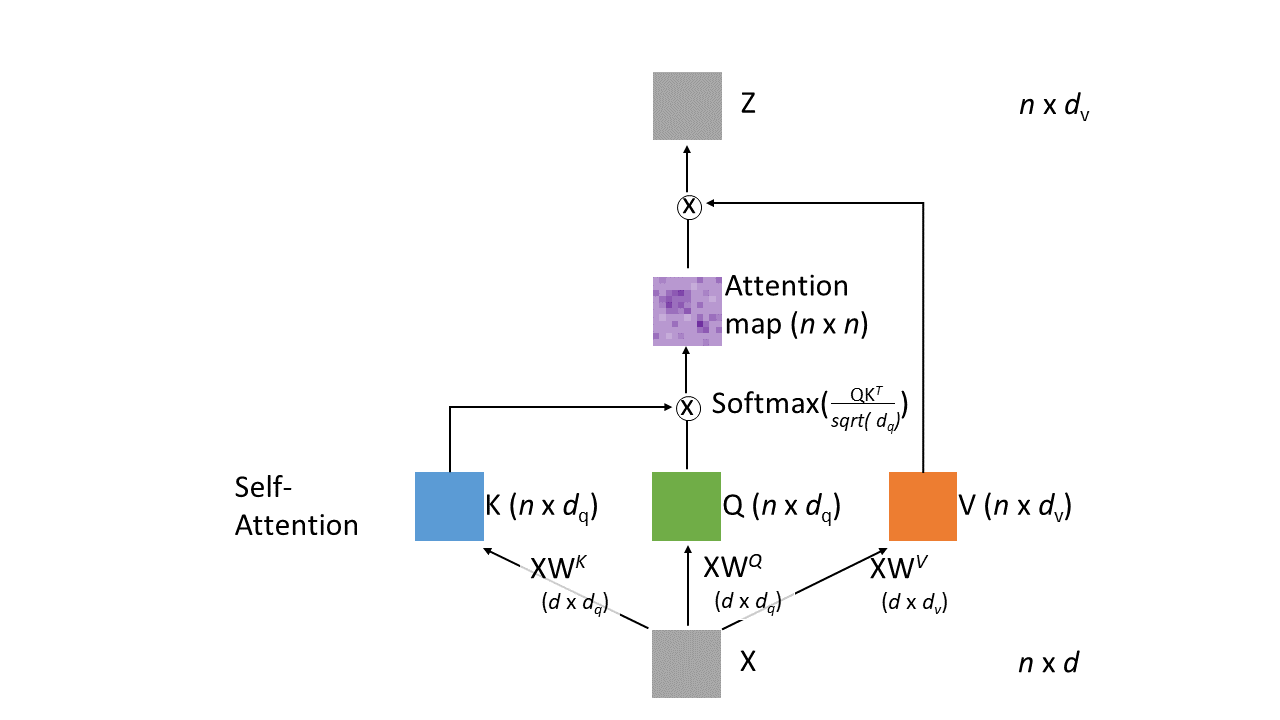
An encoded sequence of n items, labeled \(X\) in Figure 1, of dimension (\(n \times d\)), where \(d\) is the embedding dimension, is transformed by three learnable weight matrices (\(W^K\), \(W^Q\), \(W^V\)). The Key (\(K\)) and Query (\(Q\)) matrices are combined (normalized dot product, rescaled with the Softmax function) into an attention map that highlight the most important items for the task. The attention map is like a graph matrix that score the strength of the relation between items. The attention map is combined with the Value (\(V\)) matrix. Then each item become the weighted sum of all items in the sequence, where weighs are given by the attention map.
Multiheaded self-attention
The original transformer model combined multiple self-attention layers (h=8) to model complex relationships in parallel.
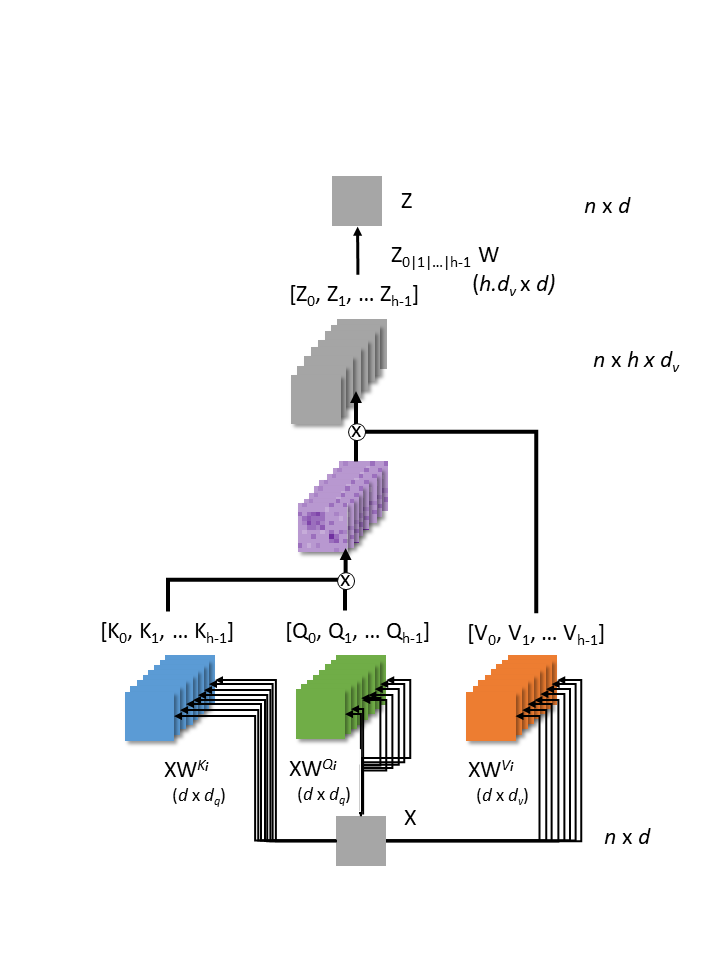
Each series of Query, Key and Value matrices are processed in parallel before the concatenation of the \(Z\) matrices. This concatenated matrix is projected onto another weigh matrix to produce an output of the same dimension as the original input (\(n \times d\)). Self-attention and multiheaded self-attention are invariant to permutation and length of the input items which make them a more general-purpose neural network layer than convolutional layers. However, self-attention layers lack local inductive bias found in CNN that makes less specialized to vision task that rely on translation invariance properties.
Vision Transformers
ViT Design
Dosovitsky et al. (Dosovitskiy et al. 2020) recently demonstrate how an adaptation of the original transformer architecture proposed by Vaswani et al. (Vaswani et al. 2017) for NLP, could replace CNN for image classification tasks.
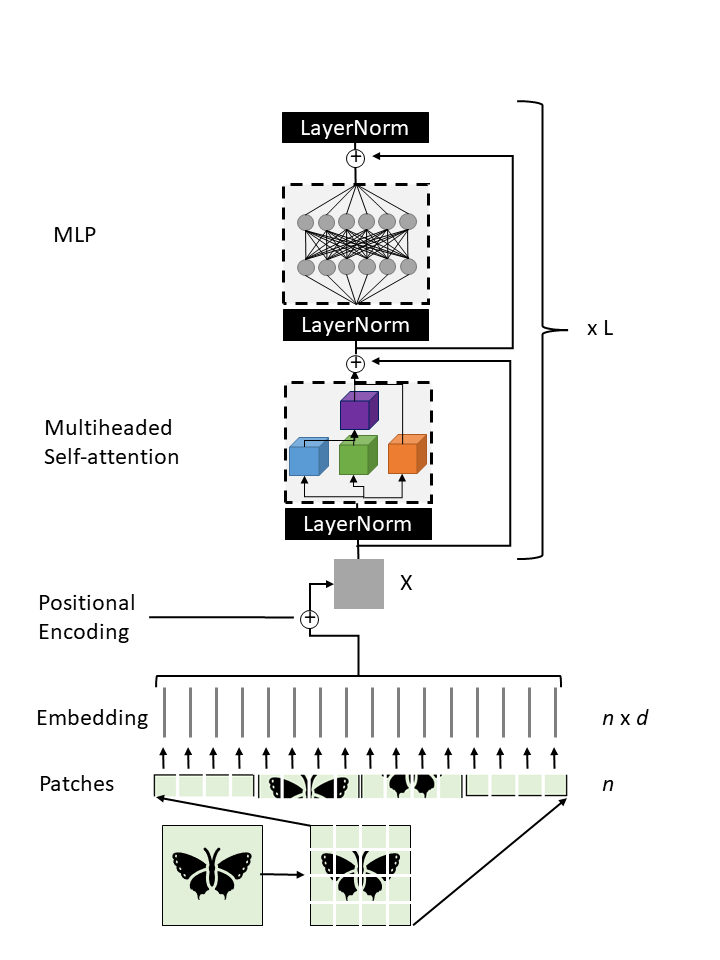
ViT is a scalable architecture (x L) that chain multiple transformer encoders. The input image is divided into \(n\) patches and tokenized through an embedding layer that transform these items into vectors of \(d\) dimensions. This vector size is constant through all the ViT layers. The positional information is encoded through the addition of the 1-dimension positional embedding. Each bock is composed of a multiheaded self-attention layer and a MLP (with a GELU non-linearity function) preceded by a layer normalization and a residual connection after every block. The last component is a regular MLP head adapted to the classification task. This architecture, pre-trained on the largest proprietary dataset (JFT 300 million images) and fine-tuned on ImageNet, was able to beat the ResNet154 based baseline.
Benefits & Limitations
- Long-range contextual information encoding is a clear benefit that allows ViT to understand the global context
- It is adapted to multi-modal tasks (images-images, image-text, …)
- Attention maps are used for explainability
- Suited to pre-training by self-supervision on unannotated data (as used for large NLP models: GPT-3)
- Higher computational cost than CNN
- Large data requirements to be competitive
ViT for Medical Images
One of the main drawbacks of ViT for medical images is the large data requirements compared to CNN. Matsoukas C. et al. (Junyu Chen et al. 2021) designed an experiment to compare CNN to ViT on medical datasets (3k to 25k images). They showed that randomly initialized CNN are more performant than randomly initialized ViT in this low data regime, however ViT are on par with CNN on the pretrained setting (transfer learning or self-supervision). The main conclusions of the authors are that ViT can replace CNN but could only outperform CNN in the self-supervised pre-training on large unannotated datasets. The improved performances come with the additional benefit of built-in high-resolution saliency map that can be used to better understand the model’s decisions.
One of the first report using transformers on biomedical images was from Prangemeier T. et al. (Prangemeier, Reich, and Koeppl 2020). They adapted the Detection Transformer (DETR) from Carion N. et al. (Carion et al., n.d.) to perform instance segmentation and demonstrated improved performance both in inference time and accuracy compared to Mask R-CNN.
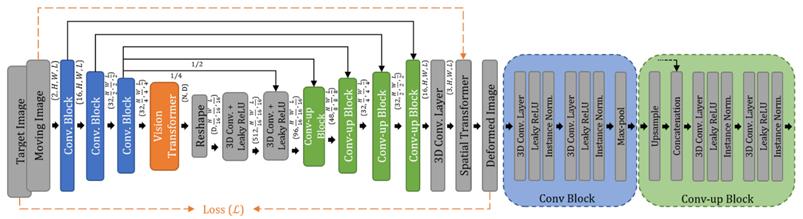
The long-range attention of ViT is particularly useful for image registration. Chen J. et al. (Junyu Chen et al. 2021) adapted the ViT for deformable image registration. They used a first CNN block as encoder for image feature encoding and another CNN block as decoder after the transformer for upscaling. Their design includes skip connections between these two CNN blocks. The inputs are the target and moving 3D volumes and the output a dense displacement field used by a spatial transformer for the warping of the moving image. The similarity of the moving and fixed volumes is used to train the algorithm in an unsupervised fashion. Their results demonstrate superior performances compared to Affine only (rigid registration), NiftyReg, SyN or VoxelMorph.
![]()
Chen J. et al. (Jieneng Chen et al. 2021) also found that the combination of CNN and skip connections with ViT achieves the best performances on the synapse multi-organ segmentation dataset (8 organs). The model called TransUNet uses a CNN encoder and patch embedding from the CNN feature map instead of raw images. The output features from the transformer encoder (Multiheaded attention + MLP layers x12) are upscaled via convolution and up-sampling and concatenation of skip-connections typical of the U-Net model. Their implementation could achieve 2 Dice point increase and 5 Hausdorff point decrease compared to similar 2D segmentation architectures such as ResNet50-UNet.
Conclusion
ViT is still in its infancy but already demonstrate promising results for medical imaging tasks. This architecture will be particularly relevant in tasks where global information patterns are important such as in image registration and the segmentation of large organs. Some research is still needed to decrease the computational cost and data efficiency of this architecture, but it will undoubtedly contribute to next generation state of the art models.